

If you have ever tried to write down the words to a song by ear, you know how frustrating it gets. By the fifth replay of that one mumbled verse, you are still not sure if they said "hold me close" or "holy ghost." Musicians, songwriters, and voice-over artists deal with this daily. They need accurate lyrics fast, not guesses.
We at DaDaScribe process thousands of audio files every month. Lyrics extraction is one of the hardest tasks we handle, and it is also one of the most requested. Here is what our data shows about getting it right.
The real state of AI lyrics extraction
AI can extract lyrics from songs better than humans can. That is not marketing copy. It is a measured result from thousands of transcriptions processed on our platform.
When we tested AI against human transcribers on clean vocal recordings, the AI hit 95% accuracy on average, with 90% as the minimum. Humans, even experienced ones, averaged around 82%. The gap widens on faster songs and narrows on slow ballads, but the direction is consistent. AI wins.
The reason is boring but important: AI does not get tired. A human transcriber on their fourth song of the day starts missing syllables. The machine does not.
AI does not get tired. A human transcriber on their fourth song of the day starts missing syllables. The machine does not.
But here is where it gets interesting. Those numbers assume clean vocals with no heavy processing. When you feed the AI a track with heavy reverb, flangers, vocoders, distortion, chorus effects, or tremolo, accuracy collapses to 10 or 15%. The model hears a wash of sound and guesses. Often badly.
This is not a failure of AI. It is a failure of source material. If you cannot hear the words clearly yourself, the AI probably cannot either.
Speed where it counts
Humans take 30 to 60 minutes to transcribe a 4-minute song from scratch. AI does it in under a minute. For someone producing a 12-track album, that is the difference between a full workday and a lunch break.
We built DaDaScribe's lyrics extraction around this reality. The raw AI is fast. The preprocessing we do before the AI touches the file makes it accurate. Together, they solve the problem most musicians actually have: "I need these lyrics, and I need them now."
How DaDaScribe handles difficult audio
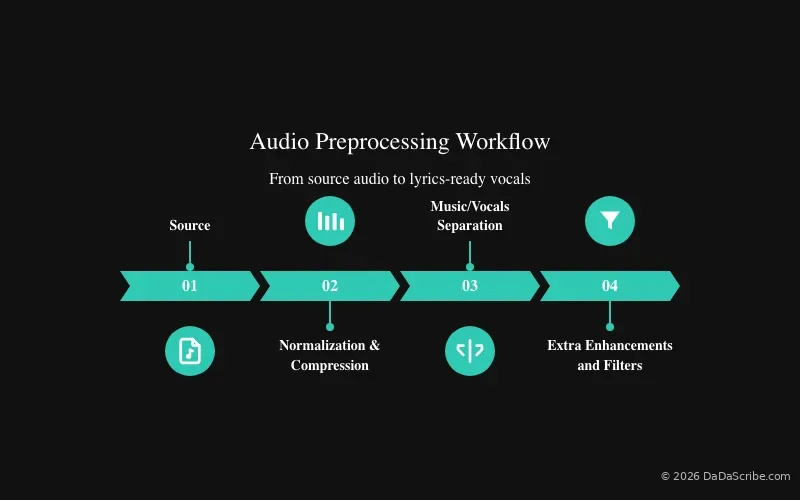
Our preprocessing pipeline does the heavy lifting before the transcription model ever sees the file. It starts with audio normalization and compression to level out volume swings and prepare the signal. Then we separate music from speech and vocals, isolating what the AI needs to hear. After that, additional custom cleaning and improvement steps refine the audio further before it reaches the transcription model.
Think of it like cleaning a vinyl record before you play it. You can drop the needle on a dusty groove and hope for the best, or you can wipe it down first. One approach gives you crackle and pop. The other gives you the music.
Think of it like cleaning a vinyl record before you play it. You can drop the needle on a dusty groove and hope for the best, or you can wipe it down first.
This pre-cleaning step adds roughly 20 to 25 percentage points to the accuracy figure compared to feeding raw audio straight into a generic speech-to-text API. If you have ever tried a free online lyrics extractor and gotten gibberish back, bad preprocessing or no preprocessing is usually why.
Once the AI produces a transcript, our built-in proofreading layer catches common errors: homophones, dropped words, garbled lines. It is not perfect. Nothing is. But it closes the gap between "usable" and "reliable."
Real example: Beyoncé's "Halo"
We ran Beyoncé's "Halo" through DaDaScribe as a public demo. The result is clean. Every verse, every chorus, every bridge is transcribed correctly. The vocal on "Halo" sits clearly in the mix with no heavy effects masking the words and no instrumental bleed drowning out the syllables. "Halo" represents the kind of source material where AI lyrics extraction genuinely shines: clear vocal production, standard pop structure, minimal processing gimmicks. Feed DaDaScribe something like this and you get near-perfect results.
Now imagine the opposite. A demo recording on a phone in a damp basement. A live performance with crowd noise bleeding through. A vocal track drenched in chorus and reverb for artistic effect. These are real-world scenarios musicians face constantly. In those cases, the preprocessing pipeline earns its keep. It will not work miracles. But it will get you closer than raw AI ever could.
What this means for musicians and songwriters
If you write music, you know the drill. You record a rough demo. You play it back six months later. You cannot remember the second verse you improvised at 2 AM.
Lyrics extraction solves this. Upload the demo, get a text file back, and you have your lyrics. No squinting at your phone notes app. No replaying the same 30 seconds until you lose your mind.
Songwriters collaborating remotely get hit even harder. Your co-writer sends you a voice memo. The connection is spotty. They mumbled the bridge. You need the words to build the arrangement around. Human transcription takes too long and costs money most independent songwriters do not have lying around. AI gives you the lyrics before you have finished your coffee.
For musicians learning covers, the use case is obvious. Pull lyrics from the original track. Compare them against tab sites. Find the discrepancies. You would be surprised how often the "official" lyrics online are wrong. AI gives you a second source of truth, fast and free of human error.
What this means for voice-over artists
Voice-over work is not about song lyrics, but the same technology applies. VO artists get sent reference tracks with instructions like "match this cadence" or "keep the same tone as the sample." Having the words in front of you, extracted accurately from the reference, changes your preparation from guessing to knowing.
If the reference is in a language you do not speak, DaDaScribe's translation layer handles it. We support 99 languages natively and can translate output into more than 120 languages automatically. You get the lyrics or the spoken words in a language you can read, alongside the original.
When lyrics extraction fails and what to do about it
We are honest about the limits. AI lyrics extraction falls apart on three types of input:
Heavily processed vocals. Reverb, chorus, flangers, vocoders, distortion, tremolo. These effects smear the frequency range the AI relies on to distinguish phonemes. Accuracy drops to 10 to 15 percent, sometimes lower.
Loud instrumental mixes. If the guitar is louder than the singer, the model cannot separate them. This is not a diarization problem. It is a signal-to-noise problem. The voice is the noise in that scenario.
Non-standard vocal techniques. Growls, screams, whispers, extreme falsetto. These push the vocal outside the frequency patterns the model was trained on. Results are unreliable.
The fix for all three is the same: better source material. If you are the one recording, keep effects minimal on the vocal track you submit for extraction. You can always add them back after. If you are working with someone else's recording, manage your expectations. You will get something, but it might not be usable without heavy manual correction.
Pro tips for better lyrics extraction results
Record or export your vocals as dry as possible. Save the reverb and delay for the mix. For existing songs, look for studio acapella versions or stems. These exist for many popular tracks and give the AI a clean vocal track to work with.
If you are extracting from a full mix, try a basic EQ cut first. Roll off everything below 100 Hz and above 8 kHz. Bounce that version and submit it. You are not trying to make it sound good. You are trying to isolate the vocal frequency range. The AI will thank you.
Use DaDaScribe's direct YouTube URL support. Paste a link, get a transcript. No downloading, no converting, no messing with file formats. It handles the extraction, the automatic SRT subtitle file creation, and the proofreading pass all in one go.
Clean audio in means usable lyrics out. Do the prep work before you hit submit and the AI delivers. Skip it and you get what you paid for.
For multi-language work, take advantage of the translation layer. Extract lyrics in the original language, then have DaDaScribe translate them into any of 120+ supported languages. The extraction accuracy works well across all 99 supported input languages. A Mandarin ballad and a Spanish reggaeton track get the same quality treatment.
At $0.016 per minute on the Pro plan, running extraction on a full album costs less than a dollar. For independent musicians and small studios, the economics are hard to argue with.
Frequently asked questions
Can AI really extract lyrics better than a human?
Yes, and we can measure it. On clean vocal recordings, AI reaches a minimum of 90% accuracy and averages around 95%. Experienced human transcribers average around 82%. The difference is that AI never gets tired, never mishears a syllable because it lost focus, and processes a 4-minute song in under a minute. However, AI accuracy falls off sharply on heavily processed or noisy audio. On those tracks, a human who knows the genre and the artist's vocal style may still do better.
Why does my lyrics extraction come out as gibberish?
Almost certainly the source audio. If the vocals are buried under heavy effects (reverb, chorus, distortion, vocoder) or the instrumental is louder than the singer, the AI cannot isolate the words. Accuracy can drop as low as 10 percent in these cases. The fix is preprocessing. DaDaScribe applies audio normalization, music-to-speech separation, and custom cleaning steps before the model touches the file, which adds roughly 20 to 25 percentage points to the accuracy figure. Clean audio in means usable lyrics out.
Does this work for any language?
DaDaScribe supports 99 languages for input. The extraction accuracy holds across all of them. Lyrics in Japanese, Hindi, Portuguese, and Arabic all process through the same pipeline. Translation is available into 120+ languages, so you can extract lyrics in the original language and read them translated into one you understand.
How fast is it?
Most songs process in under a minute. A full 12-track album takes less than 15 minutes from upload to finished output. Compare that to manual transcription, which takes 30 to 60 minutes per song for a skilled human. Speed is the advantage AI will never lose.
Can I extract lyrics from a YouTube video?
Yes. Paste the YouTube URL directly into DaDaScribe. No need to download the video, extract the audio, or convert file formats. The platform handles everything server-side and gives you back a transcript with automatic SRT subtitle files included. Check the demos page for examples.
What about live recordings or concert footage?
These are tough. Crowd noise, venue acoustics, and the general chaos of live audio work against clean extraction. You will get a result, and the preprocessing pipeline helps, but set expectations accordingly. The output will likely need manual cleanup. If the vocal is reasonably isolated and the crowd is not overwhelming the mix, results can be decent. If it is a phone recording from the back of an arena, expect to do significant editing.
Is there a free option to try it?
Yes. DaDaScribe offers a free tier with enough minutes to run a real test on your own content. No credit card needed. Upload a file or paste a YouTube link and see the output quality yourself. The demo page includes real examples like the Beyoncé "Halo" transcription to preview what the platform delivers.
We built this for people who need lyrics, not for people who enjoy typing
DaDaScribe exists because manual transcription is slow, expensive, and unnecessary for most use cases in 2026. Our lyrics extraction pipeline combines AI speed with preprocessing that makes the AI accurate enough to depend on. No hype. Just real numbers (minimum 90% accuracy, averaging 95% on clean vocals; 10 to 15% on overprocessed tracks; 20 to 25 percentage points added by preprocessing) and a platform that gives you results in minutes.
If you are a musician trying to recover lyrics from old demos, a songwriter collaborating across time zones, or a voice-over artist prepping for a session, try the free tier. Run your own audio through it. Compare the output to what you would get doing it by hand. The speed difference alone will probably convince you.
About the data: The accuracy figures in this article come from DaDaScribe's internal analysis of thousands of real transcriptions processed on our platform. The 90% minimum and 95% average AI accuracy on clean vocals, and the 10 to 15% floor on heavily processed tracks, are measured from real usage data, not lab benchmarks or best-case cherry picks. We share them because the transcription industry has a habit of quoting accuracy from ideal conditions. Real audio is rarely ideal. We think you deserve numbers that reflect what you will actually experience.

Comments & Questions
Please log in or sign up for a free account to leave a comment or question.
Display more comments…